For good or bad many sites are now using CAPTCHAs to determine if visitor is human or computer program. Captcha presents a task – usually reading some distorted letters and writing them back to a form. This is considered to be hard for computer to do, so user must be human. To improve accessibility visual captchas are accompanied by audio captchas, where letters are spelled (usually with some background noise to make letters recognition more difficult) . However audio captchas are know to be easier to break. Inspired by this article [1] I created a python implementation of audio captchas decoding using commonly available libraries and with just a general knowledge of speech recognition technologies. Software is called adecaptcha and I tested it on couple of sites, where I got 99.5% accuracy of decoded letters for one site and 90% accuracy for other site (which has much distorted audio).
General approach
We can divide task of recognizing spelled letters into 3 separate sub-tasks, each one is using a bit different technologies and approach:
- Signal segmentation
We start with continuous sound signal, where we have several spoken letters and between them there is a silence or background noise. We have to cut signal into parts that contain just one spoken letter. - Features extractions
We have to represent each sound with set of features, which characterize well each letter sound and which is not too big. We get so call features vector – a set of numbers, that we can use later for classification. - Classification
To feature vectors calculated from a letter sounds we have to assign correct letter – all sounds for same letter form same class – thus we use term classification.
Classification usually has two steps:
Learning: Based on manually classified training set (feature vector + correct letter), our classification algorithm learns how to classify arbitrary feature vector. Result of learning is the model.
Classification: Using previously created model we can now classify unknown feature vectors into classes – e.g. recognize spoken letters.
Test data
Initially we will use captchas from site uloz.to – here is one sample captcha:

and here is corresponding sound:
We usually get data as PCM signal (or if it is .mp3 we can easily decode with pymad)
So our signal looks like this (sample rate 16kHz):

As you can see there are 4 areas with high volume of sound – these are spoken letters and there is a noise between them. We can move now to our first task, segmentation:
Segmentation
Segmentation is a critical task – all future success depends on fact that we are able to identify areas, where spoken letter is in the signal. There are many sophisticated techniques used in speech recognition, with advanced options how to mitigate disruptive effects of the noise. However not being and expert I used something simple – just calculated mean energy (square of amplitude) over a small rectangular window (numpy function convolve is very useful for this). On picture below you can see this ‘energy envelope’ of the signal and planned segmentation of the signal:

We use a threshold value (green horizontal line) to find segments of sound. Anything above it is letter sound, which ends, when signal is below threshold for at least 0.1 sec. We also add a small amount of time before and after letter segment, so we get better capture of start and end of the sound. Letter sound segments are marked with vertical lines – red is start, yellow end of segment. With separated letter sounds we can start features extraction.
Features extraction
In speech recognition technologies MFCCs (Mel-frequency cepstral coefficients) are used to get features for letter or syllable sound. MFCC is basically a spectrum of frequency spectrum (applying twice time domain to frequency domain transformation) and it is believed to be good characterization of some sound, invariant to certain extent to background noise or to speaker pronunciation.
We use very straightforward implementation, based Wikipedia article:
- We make the Fourier transform of letter sound. Below you can see frequency spectrum for two letters X and B:
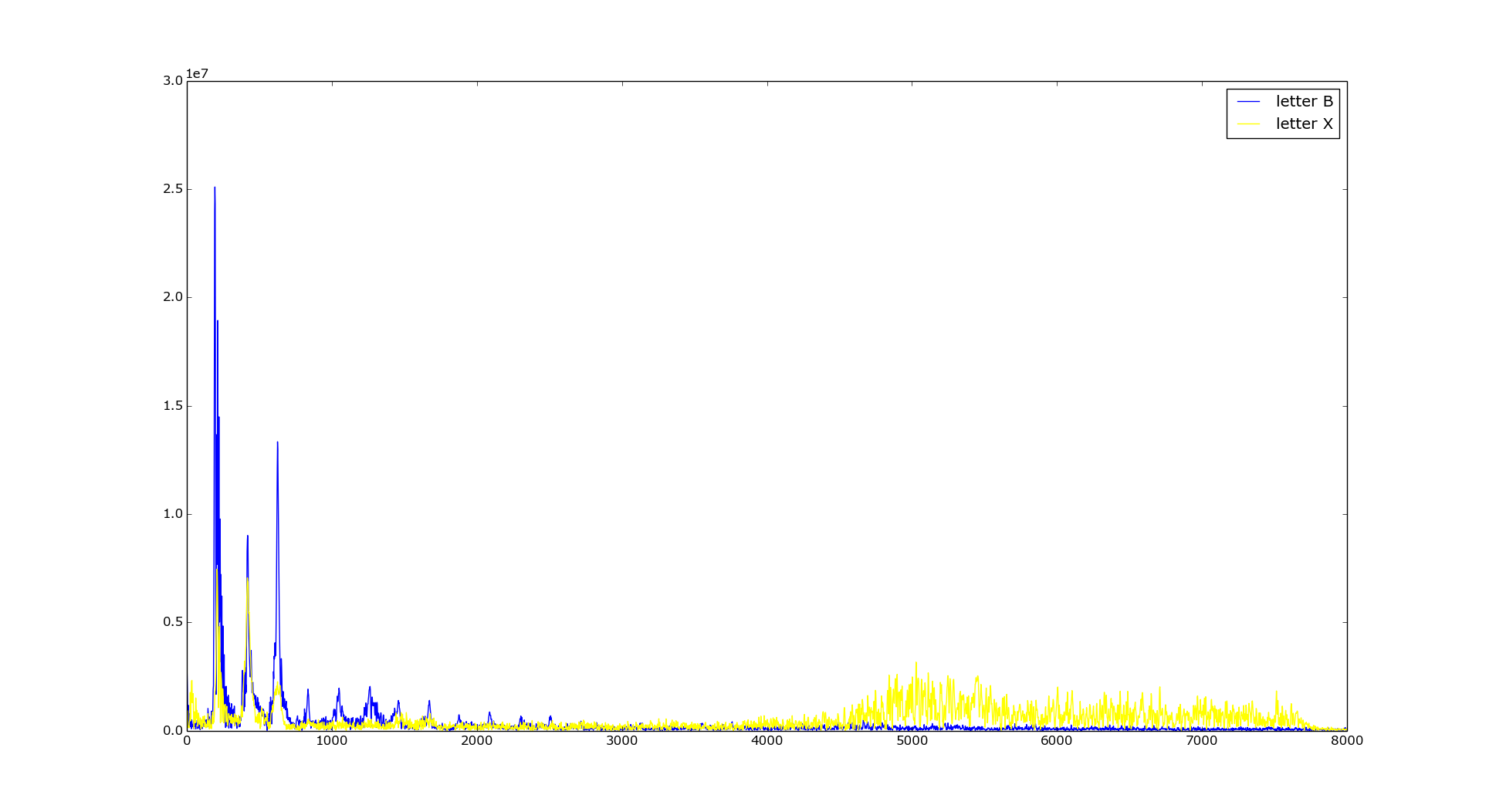
As you can see frequency characteristics of each letter are different – B having higher lower frequencies, X having significant higher frequencies (over 5kHz) – representing ‘hissing’ in the letter sound. - Map the powers of the spectrum obtained above onto the mel scale, using triangular overlapping windows.
We would like to represent spectrum only with selected frequencies – this reflect human psychoacoustics model, which tells us that we are not able to recognize two distinctive sounds if they have similar frequencies. We hear just one sound (the stronger one). This is called masking effect (and it’s used also in audio compression). Also our perception of sound pitch(frequency) is not linear – for lower frequencies we are able to recognize it more precisely, while for higher frequencies the interval between two sounds, which we perceived having different frequency, is much bigger. This is what mel scale is about – mel scale maps frequencies to a scale that is linear according to our perception.
So we can have smaller distance between frequencies on lower frequency, and bigger on higher frequencies and still keep most of information perceived by human .
Following picture shows our filter bank (each filter is triangular window):
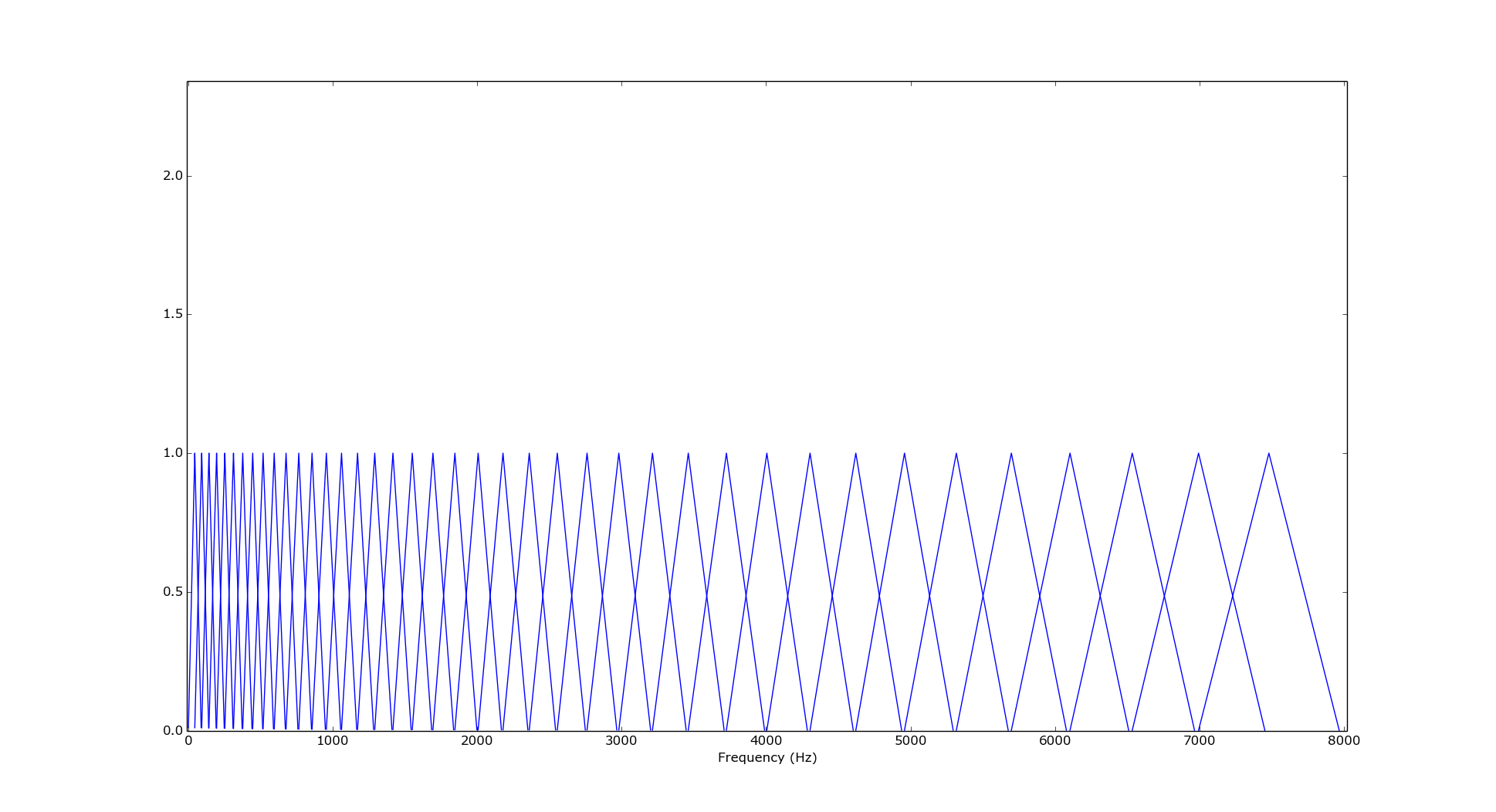
Each triangle represents a filter for frequency at triangle top. Triangles are overlapping as requested and you can clearly see how their base is getting bigger with increasing frequency (to reflect the mel scale). - Take the log of the powers at each of the mel frequencies.
Below is picture of filtered power spectrum from previous step – in log vertical scale:

You can again see spectrum characteristics of X and B letters we’ve spoken before. - Take the discrete cosine transform of the list of mel log powers, as if they were a signal.
DCT transformation is available in scipy package in scipy.fftpack.dct - The MFCCs are the amplitudes of the resulting spectrum.
And finally here we have MFCCs for our two letters:
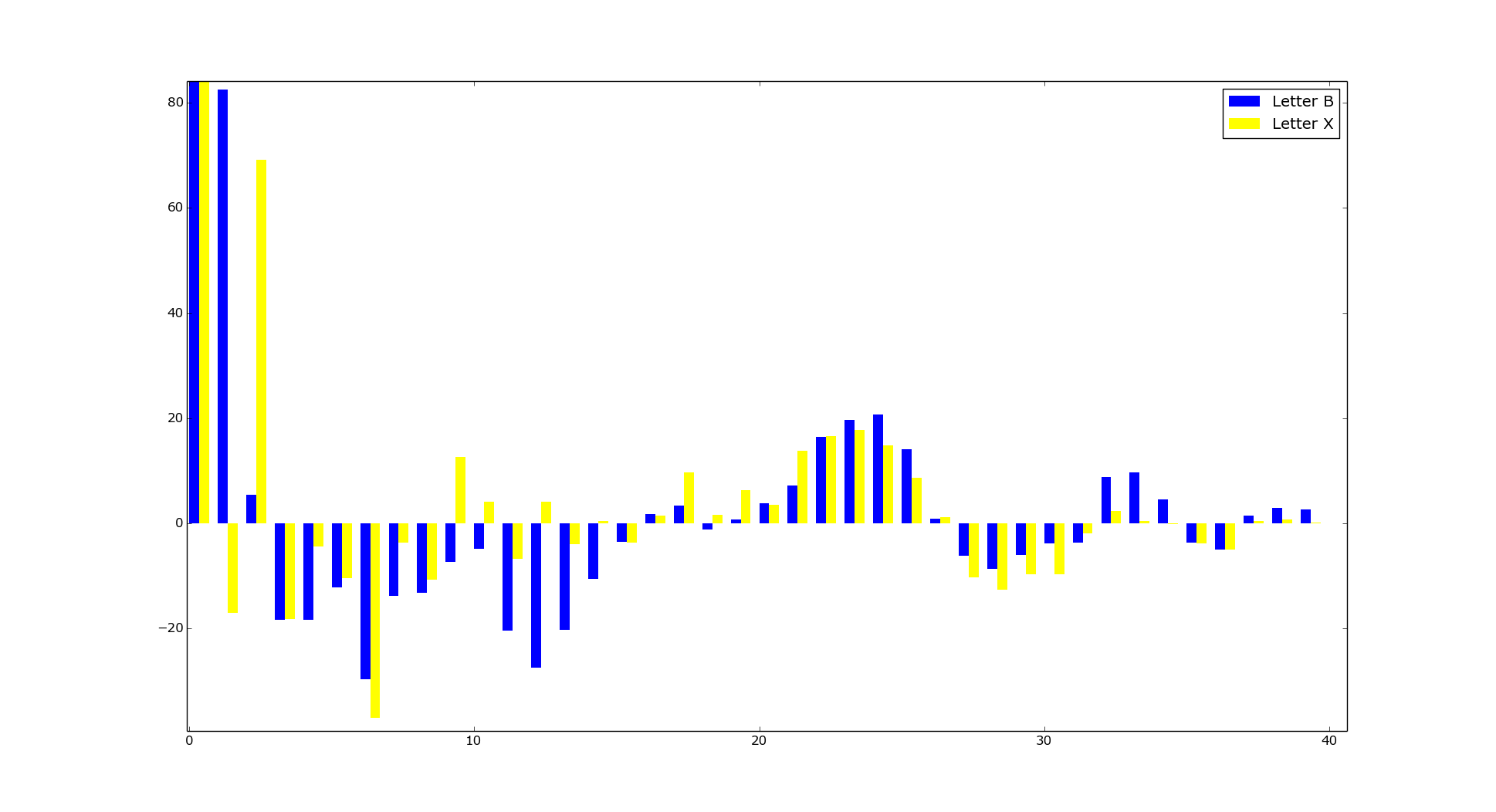
Now we have feature vector with 40 numbers and can use it for classification.
Classification
For classification we use SVM algorithm. There are several reasons for choosing it:
- According to literature [1], SVM provides good results in this area
- Nice open source implementation exists – libsvm
- libsvm has binding for python
- It’s very easy to create model for libsvm, package contains script
tools/easy.py, which basically does all work for you.
For targeted site we got 500 captchas, which represent 2000 letters – 1800 were used for training. 200 were control set, to test accuracy of classification for created model (which was 99.5%). For preparation of training set we used samplestool.py from adecaptcha package, which helps to manually classify samples (shows captcha picture, plays sound, does segmentation, saves transcribed letters, generates training set). All task of preparing training data took bit more then one hour (most time consuming is manually transcribing training captchas).
Detailed procedure for generating model is in adecaptcha README file.
Other captchas
The approach above was initially applied to uloz.to captchas, which are relatively clear, with minimum background noise. But what about site where captchas are more distorted – like these:
It turned out that we can still get 90% accuracy of individual letters (here letters are digits) recognition, which for 4 letters captchas provides app. 65% accuracy of recognizing captcha correctly. It helped here that segmentation was relatively easy and fixed segments could be used.
Conclusion
Usually it’s easier to decode audio captcha then visual one. Technology for this is available and can be used by relative laymen in area of speech recognition like myself.
Implementation in python is provided in package adecaptcha, which works quite well for test site (uloz.to) with almost 100% accuracy and it takes app. 0.3 sec to decode audio captcha – so it can be easily used in practice. Even for more noisy captchas we can achieve 65% accuracy in recognized captchas, which is still fairly practical ( only 4% of attempts need more then 3 tries).
Possible improvements:
- Better segmentation – reliable segmentation is the key, it could be improved to be more noise tolerant and more generic (parameters must be fine tuned for each set of samples to work reliably)
- MFCC implementation is the basic one – there are many improvement, which can make it better for this particular domain – recognition of spelled letters/digits
References
[1] Jennifer Tam,Jiri Sima,Sean Hyde, Louis von Ahn: Breaking Audio CHAPTCHAs
can i see source code to create triangular filterbank?
Here http://bazaar.launchpad.net/~ivan-zderadicka/adecaptcha/trunk/view/head:/adecaptcha/pwrspec.pyx
I recently updated to Cython for better performance – pure python code (look for previous revision of mymfcc.py) was several times slower.
I.
Hiya! I’m wondering about an error I get when trying this out:
$ python adecaptcha.py ulozto.cfg file://`pwd`/test.wav
Traceback (most recent call last):
File “adecaptcha.py”, line 41, in main
res=clslib.classify_audio_file(resp, args[0], ext=get_ext(resp.info()))
File “/home/snout/win2/tempfilm/new/adecaptcha-master/adecaptcha/clslib.py”, line 38, in classify_audio_file
silence_sec=cfg[‘silence’]) [cfg[‘start_index’]:cfg[‘end_index’]]
File “/home/snout/win2/tempfilm/new/adecaptcha-master/adecaptcha/audiolib.py”, line 65, in segment_audio
env=calc_energy_env(data_array,sr)
File “/home/snout/win2/tempfilm/new/adecaptcha-master/adecaptcha/audiolib.py”, line 54, in calc_energy_env
win= numpy.ones(wsize, dtype=numpy.float) / float(wsize) / 10737418.24
File “/usr/lib/python2.7/dist-packages/numpy/core/numeric.py”, line 192, in ones
a = empty(shape, dtype, order)
TypeError: ‘float’ object cannot be interpreted as an index
The file is a: “RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 8000 Hz”
I installed all the python packages mentioned on the github page, I’m fairly sure, and did the libsvm build.
Would I be somewhat correct in guessing that the A-Z in ulozto.cfg could have 0-9 added aswell, to recognize audio-captchas with mixed letters and digits?
Hi,
I think I saw this problem before. New versions of numpy are more restrictive about types – wsize is probably float but should be int. Look into other branches- I think I fixed it somewhere . This project is bit messy as it was my playground rather then ready to use solution.
I.