Organizations or teams producing manually many PDF documents might want to apply some quality checks before releasing documents. PDF checker enables to apply some basic automatic checks including searching for text presence (or lack of text), page numbering check, headings/paragraphs numbering and much more. Application is written in python and provides both CLI and web interface.
How it works?
Application is using pdfminer library to extract text from PDF documents – text is separated to individual lines (as recognized by pdfminer, which actually reconstructs lines from characters position on page) and each line is also supplemented by page number, it’s position on the page (top left point and bounding box of the line) and also some information about font used (name, variant, size).
Lines are then feed into checking algorithms (implemented as plugins), which check for issues (like finding some unwanted word). Issues are collected and then displayed together with their position in the document.
Features
- User friendly web interface with integrated PDF viewer
- One click error highlight – Click on the error and PDF viewer highlights it to you
- CLI interface to use from scripts
- Flexible – new checks can be very easily added as plugins (see below)
- Easy to deploy
Screenshots

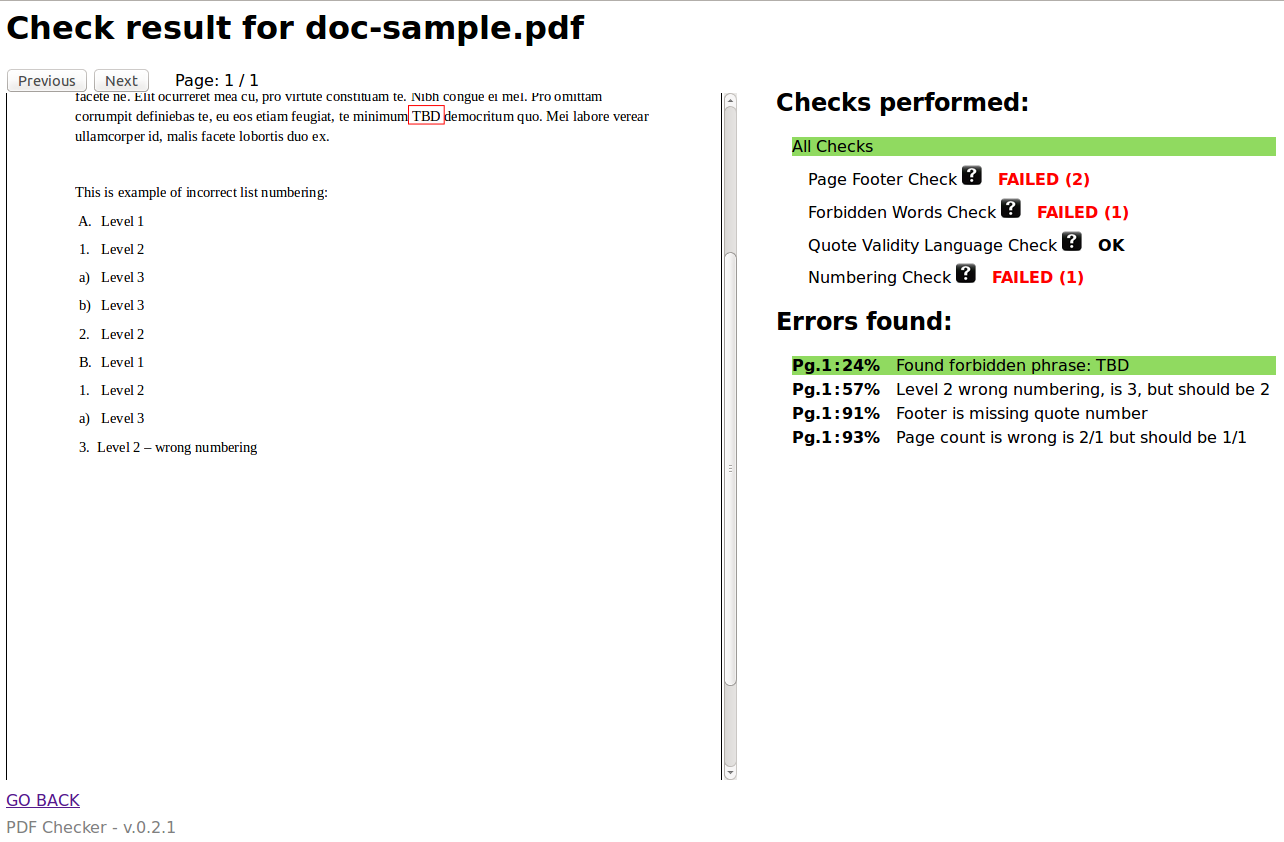
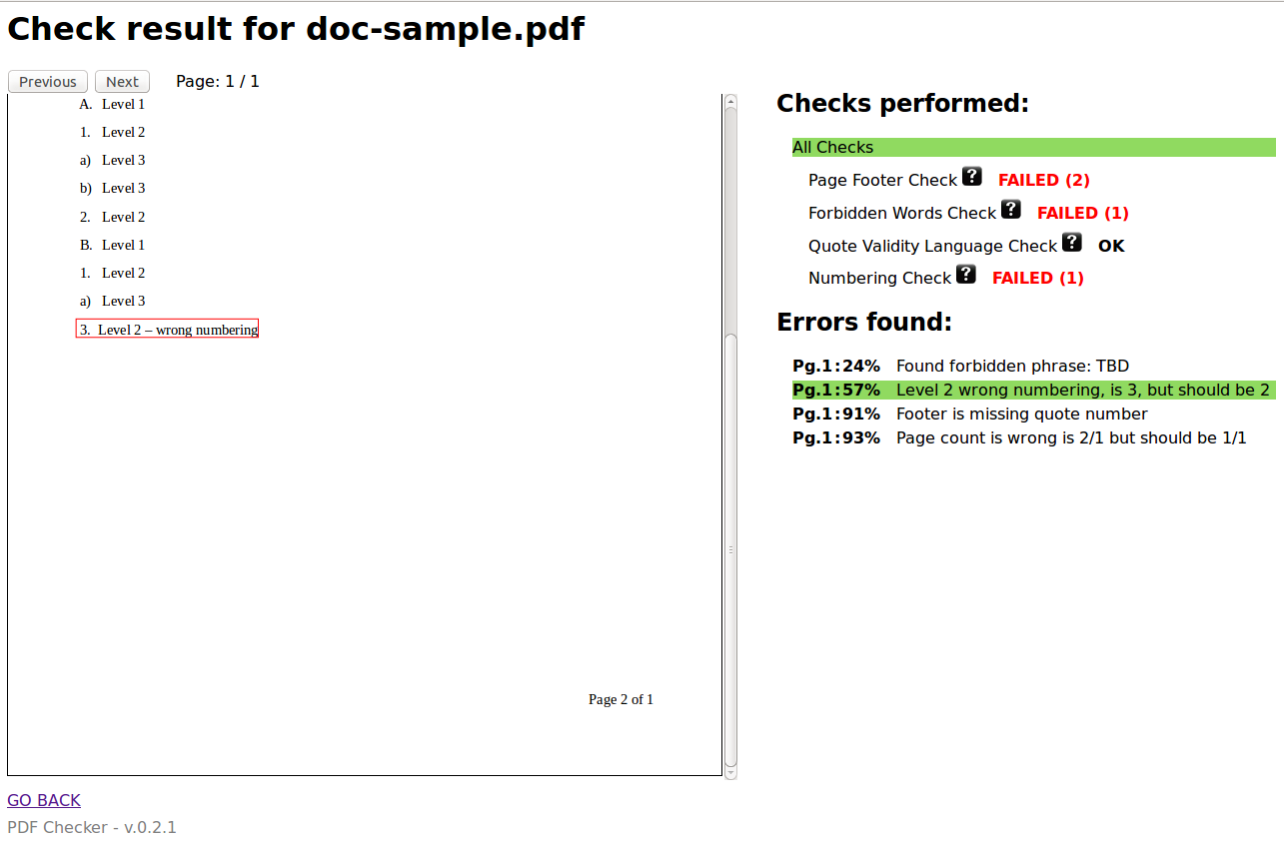

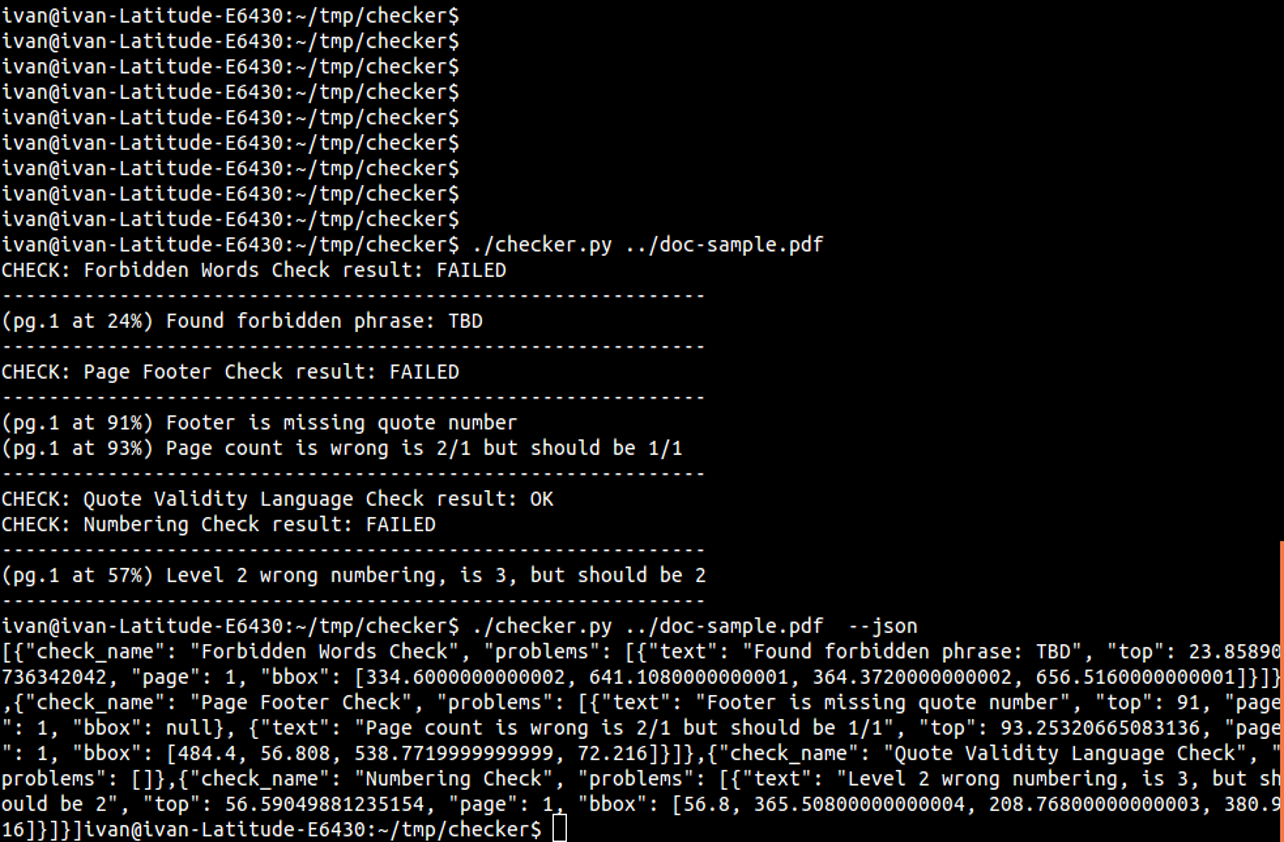
Writing Plugin
Implementing a new check is very easy. Create new module in plugins directory – here sample dummy plugin (that looks for ‘Dummy’ word in document):
import re
from common import CheckStrategy, Problem
class DummyCheck(CheckStrategy):
name="Sample Dummy Check"
help="Checks plugin tutorial"
def __init__(self,):
super(DummyCheck, self).__init__()
def feed(self, line):
for m in re.finditer('Dummy',line.text):
bbox=line.get_bbox(m.start(), m.end())
p=Problem('Found Dummy', line)
p.bbox=bbox
self.results.add_problem(p)
Plugin is a class extending CheckStrategy base class. New plugin must have class property name, with unique name of your check. Optionally it can have help and optional properties.
If you are overwriting __init__ method do not forget to call super’s __init__ .
Check is done by overriding feed method. This method will receive a line of text as it is retrieved from PDF document. Parameter line is of type TextLine, it has property text, which is string containing text of the line. TextLine has other useful properties – like page_no (page number), top and left ( relative position (in percent) of line beginning ), bbox (bounding box of text line in page coordinates). And some useful methods – like get_bbox (which gets bounding box for a substring of the line) or size_at or font_at (which gets information about font size or font name for character at given index.)
If any problem is found, it should be added to self.results collection, either via add_problem method (requiring Problem instance as an input) or just add method (which takes description of problem and line as its parameters). If results cannot be calculated on the fly, you can collect some information within feed method then and override prepare_results method, which is called at the end, when all document is processed.
That is all – check plugins are automatically loaded and used in the program. However sometime you might need to initialize check with some parameters, before using it. In this case you can supply function create_instance in plugin module code, which provides appropriately initiated instance of your check:
def create_instance():
i= ExistingCheckClass('some init params')
i.change_name('New Name')
i.change_help('New help')
return i
You can change name and help for this check, if reusing existing check with different parameters.
Download and install
Code is available under GPL v3 license.
Code can be downloaded from github. You”l need to write your own checking plugins to make it useful – because included ones are quite specific for my case.
For installation instructions check README file.